Command Query Responsibility Segregation, CQRS
Command Query Responsibility Segregation (CQRS) is a software design pattern that separates the operations that read data from those that update data. In a traditional architecture, a single data model is often used for both read and write operations. This approach is straightforward and is suited for basic create, read, update, and delete (CRUD) operations.
With CQRS, you create distinct models: one for commands and one for queries, each optimized for its specific tasks.
As applications grow, it can become increasingly difficult to optimize read and write operations on a single data model. Read and write operations often have different performance and scaling requirements. A traditional CRUD architecture doesn’t take this asymmetry into account, which can result in the following challenges:
- Data mismatch: The read and write representations of data often differ. Some fields that are required during updates might be unnecessary during read operations.
- Lock contention: Parallel operations on the same data set can cause lock contention.
- Performance problems: The traditional approach can have a negative effect on performance because of load on the data store and data access layer, and the complexity of queries required to retrieve information.
- Security challenges: It can be difficult to manage security when entities are subject to read and write operations. This overlap can expose data in unintended contexts.
Combining these responsibilities can result in an overly complicated model.
Solution: Use the CQRS pattern to separate write operations, or commands, from read operations, or queries. Commands update data. Queries retrieve data. The CQRS pattern is useful in scenarios that require a clear separation between commands and reads.
What is the CQRS Pattern?
The basic idea is that you can divide a system’s operations into two sharply separated categories:
- Queries. These queries return a result and don’t change the state of the system, and they’re free of side effects.
- Commands. These commands change the state of a system.
CQS is a simple concept: it is about methods within the same object being either queries or commands. Each method either returns state or mutates state, but not both. Even a single repository pattern object can comply with CQS. CQS can be considered a foundational principle for CQRS.
The separation aspect of CQRS is achieved by grouping query operations in one layer and commands in another layer. Each layer has its own data model (note that we say model, not necessarily a different database) and is built using its own combination of patterns and technologies. More importantly, the two layers can be within the same tier or microservice, as in the example (ordering microservice) used for this guide. Or they could be implemented on different microservices or processes so they can be optimized and scaled out separately without affecting one another. CQRS means having two objects for a read/write operation where in other contexts there’s one. There are reasons to have a denormalized reads database, which you can learn about in more advanced CQRS literature.
Trade-offs
One of the primary trade-offs when adopting the CQRS pattern is the increased architectural complexity it introduces. By segregating the read and write operations into separate models, you are essentially managing two different pathways for data, which can complicate your design and maintenance efforts. This division not only demands careful planning and coordination but also often results in eventual consistency—meaning that updates made on the write side may not immediately reflect on the read side. For applications where immediate data accuracy is critical, this delay could be problematic. Moreover, integrating CQRS typically requires additional patterns such as event sourcing, which further increases the learning curve and initial development overhead for teams unfamiliar with these concepts.
Beyond the architectural challenges, adopting CQRS can lead to greater operational and infrastructural demands. The need for synchronization mechanisms between the command and query models often necessitates extra tools and resources, potentially increasing the cost and complexity of your infrastructure. Testing becomes more rigorous as well, since both sides of the system must be validated independently as well as in concert, thereby extending the scope of unit and integration tests. While the pattern can significantly improve scalability and performance for complex, high-load systems, for simpler applications the overhead of CQRS might not be justified. Ultimately, the decision to use CQRS should be based on a careful evaluation of your application’s specific requirements, weighing the benefits of scalability and clear separation against the potential for increased development and maintenance complexity.
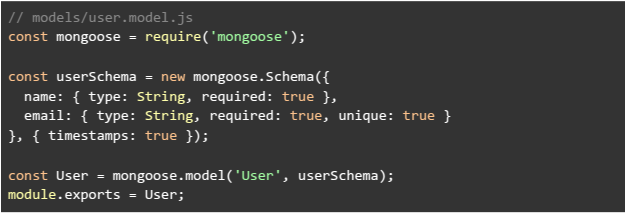
Below is an example of a fuller CQRS project structure using Mongoose for a User entity. The project is organized into separate folders for models, command operations, and query operations. A typical folder structure might look like this:

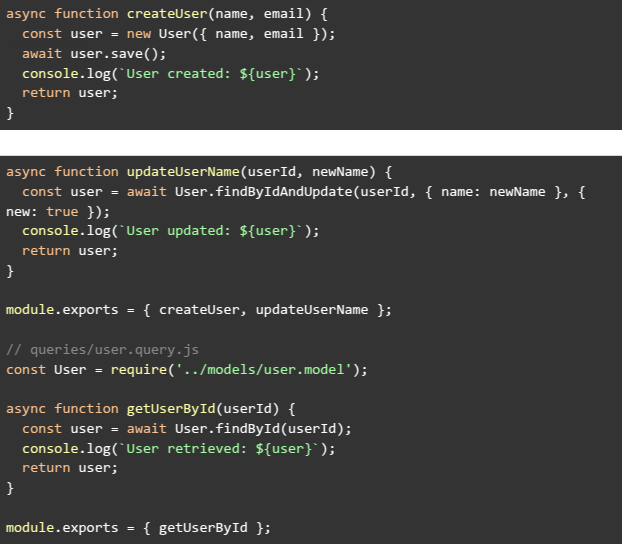
In this setup, the models folder contains the Mongoose schema and model definitions (e.g., user.model.js). The commands folder is responsible for write operations, such as creating or updating a user, while the queries folder contains the read operations to retrieve user data. For example, the command module might have functions like createUser and updateUserName, and the query module includes a function such as getUserById. Here’s how the code for these modules could look:

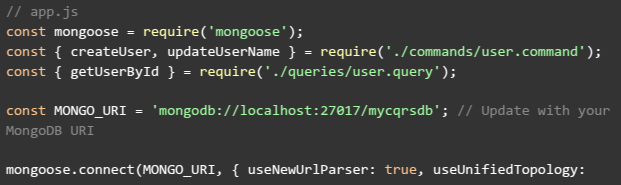
Finally, the app.js file ties everything together by connecting to MongoDB and demonstrating the CQRS operations. In this file, you can perform commands to modify data and then queries to retrieve it, showcasing the separation of concerns inherent in CQRS:
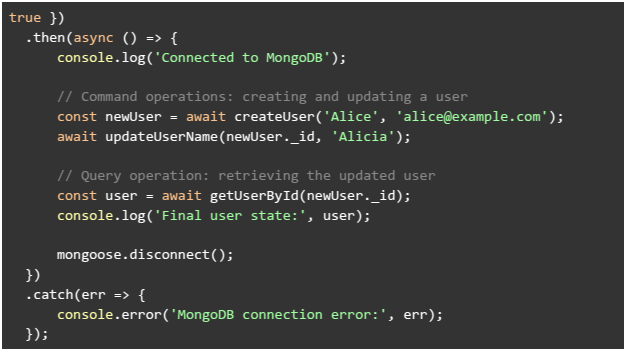
This example demonstrates a full CQRS implementation in a Node.js project using Mongoose. The project structure cleanly separates the models, commands, and queries, making the code more maintainable and scalable. Each module has a clear responsibility: the model defines the data structure, the commands handle state modifications, and the queries manage data retrieval without side effects.
Conclusion
In summary, the CQRS pattern offers a robust framework for separating the responsibilities of reading and writing data. This separation can lead to improved scalability and maintainability, especially as applications grow more complex. By isolating the command side from the query side, you can optimize each pathway independently—allowing for focused improvements in performance and clarity of your codebase.
However, this approach also comes with its own set of challenges. The increased architectural complexity, the need for synchronization between models, and the potential for eventual consistency require careful planning and a solid understanding of your application’s requirements. The code examples provided with Mongoose schemas illustrate how these concepts can be implemented practically, but they also highlight the additional overhead involved in managing a dual-model system.
Ultimately, CQRS is a powerful tool in your architectural toolkit, best suited for scenarios where the benefits of clear separation and scalability outweigh the complexities introduced. By weighing these trade-offs and considering the specific needs of your project, you can decide whether CQRS is the right choice to build more efficient and maintainable systems.